Pre-attentive processing

|
Understanding how pre-attentive processing works is not only useful to predict cognitive ability, it is also beneficial in advertising, in education, and in creation of the effective attention model. Symmetry is considered a pre-attentive feature that enhances recognition and reconstruction of shapes and objects. Water reflection is an interesting case of imperfect symmetry that frequently attracts artists and photographers. Because of water waves, motion blur causes distortions in water reflection images challenging existing symmetry detection and recognition techniques. To address these difficulties in water reflection recognition, I constructed a novel pre-attentive feature space composed of motion blur invariant moments. I also developed an effective algorithm and achieved good performance in classification and detection tasks.
|
|
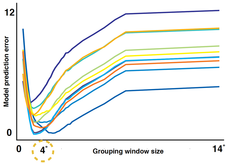
To understand underlying algorithm of human cognition and perception, I investigated pre-attentive processing from the perspective of computational models. Perceptual grouping is known to be a rapid, pre-attentive process that gives rise to “higher-units” of representation as generated by an interpretation of configurations in an image. Although the validity of the perceptual grouping was intuitively apparent to observers, formal descriptions of the mechanisms underlying them have been lacking. My research aimed to build a connection between this rapid global processing for perceptual groups and ensemble representations. Our results suggest that perceptual groups may serve as units for representation of approximate numbers, allowing for rapid extraction of ensemble features from briefly flashed visual scenes.
|
Visual cortex processing
|
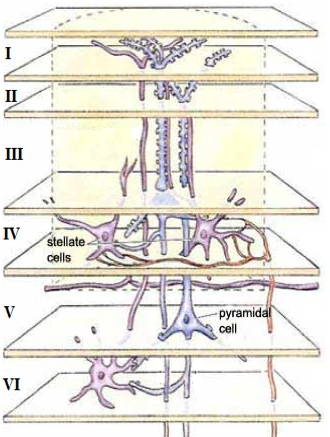
The visual cortex is the most important part in human brain responsible for processing visual information. Deep architecture composed of multiple layers of parameterized nonlinear modules has achieved notable success in modeling the human brain. Based on deep architecture, I proposed three deep learning models by borrowing the multi-layer presentations and perception procedure of brain. Unlike most existing deep learning models, Bilinear deep belief networks (BDBN) utilized a bilinear discriminant strategy to simulate the “initial guess” in human object recognition, and at the same time to avoid falling into a bad local optimum. BDBN kept the tensor structures and provided a human-like understanding of the “meaning” of the real world image. To address the difficulties of recognition for incomplete data, I designed a novel second-order deep architecture with Field effect restricted Boltzmann machines, which modeled the reliability of the delivered information according to the availability of features. The proposed model demonstrated impressive recognition performance by seeking recognition discriminant boundaries and estimating missing features jointly. Besides the data representation and classification problems, I also worked on the text and sematic processing. By extracting useful semantic information from multiple documents, Query-oriented deep extraction (QODE) showed the distinguishing extraction ability for multi-document summarization applications.
|
|
|
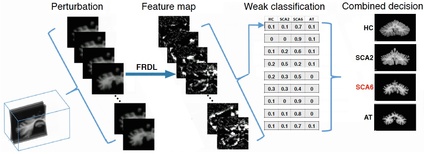
Based on above computational models, I implemented a deep learning classification and regression system for the cerebellar ataxia diagnosis and disease related functional score evaluation. Experiments showed that our approach could reliably classify the healthy controls & different types of ataxia, and predict the functional staging score for ataxia.
|
|
|
I do not only satisfy to simulate the macro-scale presentations and procedure of brain, I also want to understand the micro-scale function of neurons and finally improve the ability of computational models. As we know, noise exists universally in multimedia data, especially in Internet era. Intuitively, these noisy data are harmful to learning models. However, limited theoretical and practical evidences have been reported on real-world datasets after extensive review for this problem. Violating the intuition that noisy data always impair the learning ability, my findings illustrate the magic effect of the noisy images to deep learning model as a part of unsupervised training data. To this surprising result, one possible conjecture can be inspired from brain science. Neuroscientists provide the evi-dence that noise is a critical element of brain’s learning ability, which allows the brain to test out so many possible solutions. The noisy data would introduce the dynamic perturbations within the model just like the noise in brain cause the fluctuation of synaptic patterns. These findings help me to explore more engineer solutions by capturing the micro-scale characters in human cortex.
|
|
Visual attention

|
As a cognitive process of selectively concentrating on one aspect of the environment while ignoring other things, attention has been referred to as the allocation of processing resources. Visual attention modeling is applied frequently in many real-world applications, such as image/video representation, object detection and recognition, object tracking, and robotics controls. Related with the visual attention, I proposed three novel saliency map models to measure of conspicuity of different multimedia content and calculate the likelihood of a location to attract attention. The first proposed model was applied for the task of image quality assessment. Unlike existing metrics focused on measuring the blurriness in vision level, my metric was more concerned about the image content and human’s intention. Empirical validations demonstrated the effectiveness of the proposed saliency map model and image quality metric.
|
|
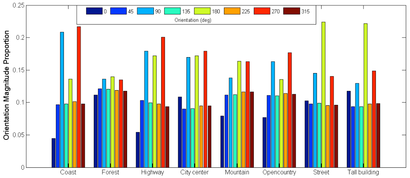
Based on the inhomogeneity of brain visual orientation perception, a novel algorithm S-SIFT was proposed to detect and describe local features in image. Experimental results demonstrated that the proposed algorithm yielded better results for feature detection and matching tasks, and comparable performance for object classification problem.
|
|
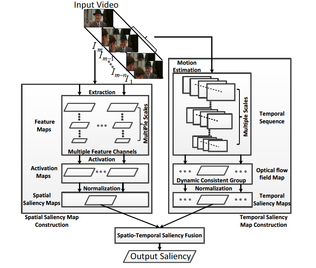
Video saliency detection involves assigning a saliency probability to each location in an image relative to its neighbors, both spatially and temporally. Quite a bit of work has focused in this domain for static images, but little by comparison has explored video sequences. I proposed a novel perception-oriented video saliency detection model called dynamic consistent saliency detection (DCOF). Empirical validations demonstrated that the salient regions detected by the proposed saliency map model highlight the dominant and interesting objects effectively and efficiently. More importantly, the video attended regions were consistent with human subjective eye tracking data.
|
Contextual cueing
|
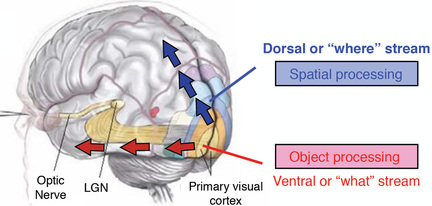
Contextual cueing is a concept in psychology and brain science that refers to a processing of individual image elements in relation to their environments. Several types of spatial invariants are thought to be important in contextual cueing including, probability, co-occurrence, size, position and spatial topology. For the task of label to region assignment, the existing techniques only relied on the similarity of images on a visual level. Different from existing techniques, a novel technique called Fuzzy-based Contextual-cueing Label Propagation (FCLP) was proposed to imitate the contextual cueing process. The experiments demonstrated that the proposed technique has shown obvious performance improvement of label to region assignment for the images with multiple objects and complex background.
|
|
